Habt ihr euch schon einmal gefragt, welche der populärsten Programmiersprache eigentlich die schnellste bzw. performanteste ist? Um das zu testen, habe ich mir ein kurzes Skript/Programm überlegt, das die Summe aller Zahlen von 0 bis 100000000 in einer Schleife errechnen muss. Das lässt sich als Konsolenausgabe in allen Sprachen umsetzen und braucht einiges an Rechenleistung – also perfekt für einen Vergleich geeignet. Das Ergebnis ist zum Großteil wie erwartet, überrascht aber auch bei manchen Sprachen.
Die Reihenfolge der Ergebnisse ergibt sich übrigens aus populärsten Sprachen aus GitHub.
JavaScript (Node.js 6.11)
var sum = 0 for (var i = 0; i < 100000000; i++) { sum +=i } console.log(sum); |
$ time node time.js 4999999950000000 real 0m0.247s user 0m0.226s sys 0m0.017s |
Python 3.6
sum = 0 for i in range(100000000): sum += i print(sum) |
$ time python time.py 4999999950000000 real 0m18.588s user 0m18.558s sys 0m0.019s |
Java 1.8
public class Time { public static void main(String[] args) { long sum = 0; for(long i = 0; i < 100000000; i++) { sum += i; } System.out.println(sum); } } |
$ time java Time 4999999950000000 real 0m0.177s user 0m0.145s sys 0m0.025s |
Ruby 2.4
#!/usr/bin/ruby sum = 0 for i in 0..99999999 sum += i end puts sum |
$ time ruby time.rb 4999999950000000 real 0m5.385s user 0m5.338s sys 0m0.026s |
PHP 7
#!/usr/bin/php <?php $sum = 0; for ($i = 1; $i < 100000000; $i++) { $sum += $i; } echo $sum . PHP_EOL; ?> |
$ time php time.php 4999999950000000 real 0m2.298s user 0m2.273s sys 0m0.014s |
C++
#include <iostream> using namespace std; int main() { long sum = 0; for(long i = 0; i < 100000000; i++) { sum = sum + i; } cout << sum << endl; return 0; } |
$ time ./time 4999999950000000 real 0m0.220s user 0m0.216s sys 0m0.002s |
C
#include <stdio.h> int main() { long sum = 0; for(long i = 0; i < 100000000; i++) { sum = sum + i; } printf("%ld\n", sum); return 0; } |
$ time ./time 4999999950000000 real 0m0.212s user 0m0.208s sys 0m0.002s |
Bash
Hinweis: Bash ist mit den großen Zahlen leider überfordert. Das Skript arbeitet daher mit einer geringeren Gesamtsumme, kommt aber selbst dort auf eine Laufzeit, die weit über dem Durchschnitt liegt.
#!/bin/bash sum=0 for i in {0..9999999}; do let sum=$sum+$i done echo $sum |
$ time ./time.sh 49999995000000 real 1m59.923s user 1m55.809s sys 0m3.687s |
Balkendiagramm
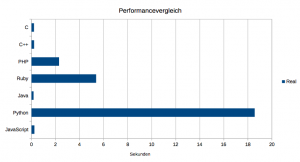
Fazit
Dass C, C++ und Java das Feld anführen, ist wenig überraschend.
Allerdings steht mit JavaScript die erste Skriptsprache unmittelbar dahinter und macht damit deutlich, warum sie sich als meistgenutzte Sprache bei GitHub durchgesetzt hat.
PHP schlägt in puncto Performance seine direkten Konkurrenten Python und Ruby mit ordentlichem Abstand.
Bash musste ich wegen des miserablen Ergebnisses sogar aus dem Balkendiagramm herausnehmen.
Hat mich erstaunt – Java bei diesem Test schneller als C. Hab das mit Optimierung getestet:
gcc -O3 time.c -o time
time ./time
4999999950000000
real 0m0.002s
user 0m0.000s
sys 0m0.000s
und die Python Version mit zwei verschiedenen Interpretern (CPython 3.5 und PyPy 2.7)
time python3 time.py
4999999950000000
real 0m12.918s
user 0m12.760s
sys 0m0.156s
time pypy time.py
4999999950000000
real 0m0.375s
user 0m0.368s
sys 0m0.004s
ca. 2 Millisekunden für C – hat mir keine Ruhe gelassen:
100 Millionen Loops in 2 ms – entspricht 50 Milliarden in einer Sekunde.
Das kann nicht sein bei einem Prozessor mit ca. 3 GHz Takt.
Der Compiler optimiert mit -O3 soweit, dass er schon das Endergebnis berechnet.
Den For-Loop um Faktor 50 vergrößert verhindert diese Optimierung:
time ./time
-5946744076209551616
real 0m1.812s
user 0m1.808s
sys 0m0.000s
-5946744076209551616 ist nicht falsch, es gibt hier nur einen Überlauf weil sum vorzeichenbehaftet ist, entspricht (12499999997500000000 – 2**64). Die 1812 Millisekunden entsprechen geteilt durch 50 ca.
30 Millisekunden.
Yezzz Python ist langsam. Mit Numba ein wenig schneller …
####
from numba import jit
@jit
def time():
sum = 0
for i in range(100000000):
sum += i
return sum
print(time())
####
time python time.py
4999999950000000
real 0m0.463s
user 0m0.393s
sys 0m0.066s
@Manfred
obigen Numba Code mit
5000000000
=>
time python time.py
-5946744076209551616
real 0m0.474s
user 0m0.401s
sys 0m0.068s
bzw.: * 1000000 … ?!
500000000000000
=>
time python time.py
634368033788157952
real 0m0.477s
user 0m0.404s
sys 0m0.068s
;^)
Habe C/C++ mit Assembler verglichen: Assembler ist 6x schneller als C/C++.
section .text
global _start
_start:
mov rax, 99999999
mov rbx, 0
.loop:
add rbx, rax
sub rax, 1
jne .loop
mov rax, 60
mov rdi, 0
syscall
Java in 0,18 Sekunden? In der Zeit lädt er bei mir nicht mal die Java Runtime !?
Mir fehlt in diesem Vergleich Perl, in dem zum Beispiel der weit verbreitete Home-Automation-Server FHEM geschrieben ist. Soweit ich an anderer Stelle gesehen habe, ist es noch wesentlich schlechter als Python.
Himmel, das ist doch kein Benchmark…
Integer sind immutable Objects in Python (die noch dazu beliebig groß werden können), keine Primitiven. Natürlich kommt Python bei diesem, wirklich aus dem Leben gegriffenen, Hirnriss nicht hinterher.
Hier wird also 100 Millionen mal ein (recht großes) Objekt instanziiert, dass dann wieder weggeräumt werden muss.
Bei dem Java Beispiel muss man auch nur von „long“ auf „Long“ umstellen um die Laufzeit zu verzehnfachen.
Wenn man das in Python macht, wie man das so macht:
print(sum(range(100000000))) )
braucht es nur noch ein Zehntel der Zeit.
Sorry, das war nix.
@Thomas:
Ich glaube, dass du nicht verstanden hast, worum es bei diesem Test ging. Es ging darum zu testen, welche Sprache bei gleichen Operationen am schnellsten ist und nicht darum, mit welcher Sprache sich die effektivste Lösung erarbeiten lässt. Ich kann die Performance ja nur richtig vergleichen, wenn alle Programme den gleichen Ablauf haben.
Es gibt übrigens eine noch viel effektivere und schnellere Lösung als deine. Dazu nimmt man einfach die Gaußsche Summenformel. Die lässt sich in allen Sprachen verwenden und kommt ganz ohne Schleifen oder Core-Funktionen aus.
n = 100000000sum = (n-1)*n/2
print(n)
Ergebnis:
4999999950000000.0real 0m0,108s
user 0m0,091s
sys 0m0,017s
Aber wie gesagt, darum ging es in diesem Benchmark-Test nicht.
@Basti:
Ich habe das schon verstanden. Aber das hier sind alles keine Vergleiche.
Die ASM-Lösung und mit ziemlicher Sicherheit auch die C-Lösung passen in eine Cache-Line des L1-Cache. Vermutlich passt der Assembler sogar in den μop-Cache (spricht Fetch- und Decode-Zyklen fallen auch weg).
Will sagen, die laufen ohne irgendeinen Hauptspeicher-Zugriff. Das kann ein Interpreter gar nicht leisten. Bei Java und JS wird der Hotspot vermutlich noch im L3 ablaufen, wenn der JIT fertig ist.
Das sind alles Effekte, die man (eigentlich) erstmal weg nivellieren will.
Außerdem: bei Java hat man ja auch Primitives anstelle von Objects genommen weil es der Sprache und dem Problem entgegen kommt.
Kurzum: der Algorithmus ist viel zu klein und macht viel zu wenig, als das er irgendeine Aussagekraft hätte.
@Thomas:
Da bin ich anderer Meinung. Der Test zeigt eine simple Operation (Schleife mit Addition) und genau das sollte auch mit allen Sprachen auf die gleiche Weise abgebildet werden. Dass durch die unterschiedlichen Arbeitsweisen im Hintergrund (durch Interpreter usw.) auch unterschiedliche Performanceergebnisse erzielt werden, sollte klar sein. Wenn alle gleich arbeiten würden, wären alle gleich schnell und wir bräuchten diesen Vergleich nicht.
Ich finde auch, dass gerade durch diesen kleinen Algorithmus überhaupt erst eine Vergleichbarkeit entsteht. Bei größeren Algorithmen oder komplexen Programmen wären innerhalb einer Sprache schon zu viele Lösungswege möglich, die einen Unterschied in der Performance ausmachen können, ein Vergleich mit verschiedenen Sprachen daher völlig witzlos.